什么是联邦学习
本质:联邦学习本质上是一种分布式机器学习技术,或机器学习框架。
目标:联邦学习的目标是在保证数据隐私安全及合法合规的基础上,实现共同建模,提升AI模型的效果。
前置知识:
IID:独立同分布,表示一组随机变量的概率分布都相同,而且相互独立。例如掷色子。联邦学习背景下,数据集是非独立同分布的。
SGD: 梯度下降算法
绝大多数机器学习模型都有一个损失函数,来衡量预测值与实际值的差异。损失函数的值越小,模型的精确度就越高。通过使用梯度下降来调节参数,进而最小化损失函数。
损失函数里一般有两种参数,一种是控制输入信号量的权重(Weight, 简称 w ),另一种是调整函数与真实值距离的偏差(Bias,简称 b )。我们所要做的工作,就是通过梯度下降方法,不断地调整权重 w 和偏差b,使得损失函数的值变得越来越小。
通过计算梯度可以找到下降的方向,然后通过学习率a来控制下降的快慢。
def train(X, y, W, B, alpha, max_iters): '‘’ 选取所有的数据作为训练样本来执行梯度下降 X : 训练数据集 y : 训练数据集所对应的目标值 W : 权重向量 B : 偏差变量 alpha : 学习速率 max_iters : 梯度下降过程最大的迭代次数 ''' dW = 0 # 初始化权重向量的梯度累加器 dB = 0 # 初始化偏差向量的梯度累加器 m = X.shape[0] # 训练数据的数量 # 开始梯度下降的迭代 for i in range(max_iters): dW = 0 # 重新设置权重向量的梯度累加器 dB = 0 # 重新设置偏差向量的梯度累加器 # 对所有的训练数据进行遍历 for j in range(m): # 1. 遍历所有的训练数据 # 2. 计算每个训练数据的权重向量梯度w_grad和偏差向量梯度b_grad # 3. 把w_grad和b_grad的值分别累加到dW和dB两个累加器里 W = W - alpha * (dW / m) # 更新权重的值 B = B - alpha * (dB / m) # 更新偏差的值 return W, B # 返回更新后的权重和偏差。
优化过程
固定总数 K 个客户端,每个客户端都有本地数据集。
每次选取分数 C (比例)个客户端
服务器将当前的全局算法发送给每个客户端。
每个被选定的客户端执行本地计算,并将服务器更新。
通信成本占主导
一般数据中心中,通讯花费占少数,计算花费占大头。但是在联邦优化中,通讯占主导地位
通常上传带宽被限制到1MB或者更低。
客户端只有在充电,插入电源,和有不限量WIFI的情况下才会参与到优化过程中来。
希望每个客户每天只参加少量的更新回合。
因为单个客户端的训练数据很小,而且当前智能手机等客户端的计算能力是足够强的,所以通过使用额外的计算量来减少通信的次数
增加并行量。在每次通信过程中,使用更多客户端来更新。
增加每个客户端的计算量。
联邦平均算法
联邦背景下,对梯度下降算法的扩展。
选取K个Client,Server将当前的参数传递给Client,Client根据本地数据集和参数来进行梯度下降。
最后将训练后的参数返回给Server,Server将获得的所有参数加权处理后得到最终的参数。然后再进行下一轮计算。

如图所示,当B $\rightarrow$ $\infty$,E $\rightarrow$ 1 表示本地数据全部参与训练,只训练一次,称为FedSGD。
分类
我们把每个参与共同建模的企业称为参与方,根据多参与方之间数据分布的不同,把联邦学习分为三类:横向联邦学习、纵向联邦学习和联邦迁移学习。
横向联邦学习
横向联邦学习的本质是 样本的联合,适用于参与者间业态相同但触达客户不同,即特征重叠多,用户重叠少时的场景,比如不同地区的银行间,他们的业务相似(特征相似),但用户不同(样本不同)
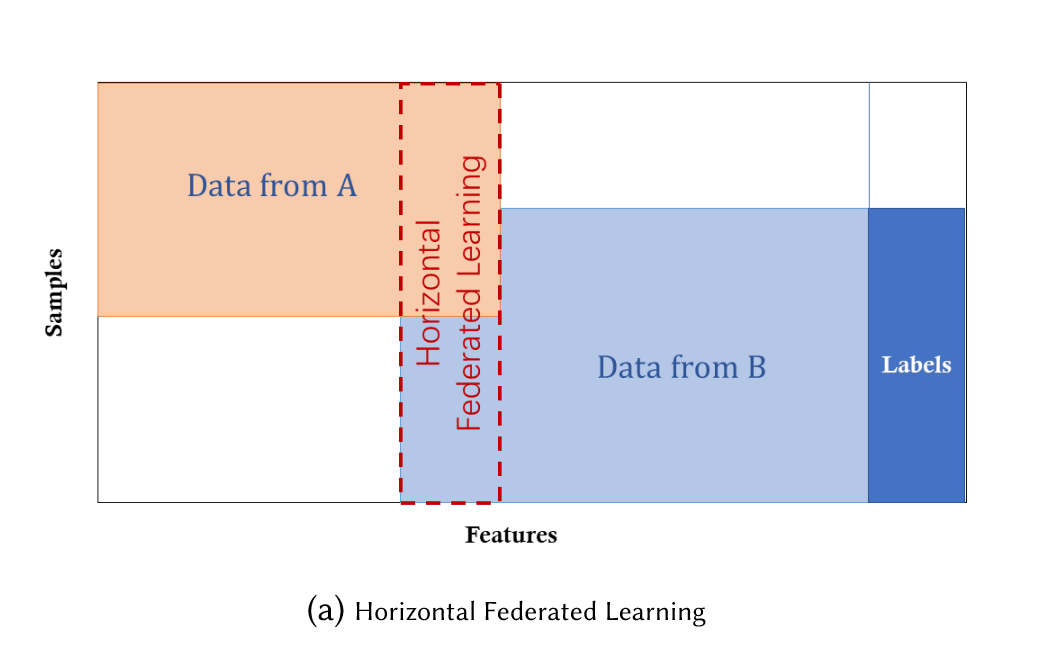
学习过程:
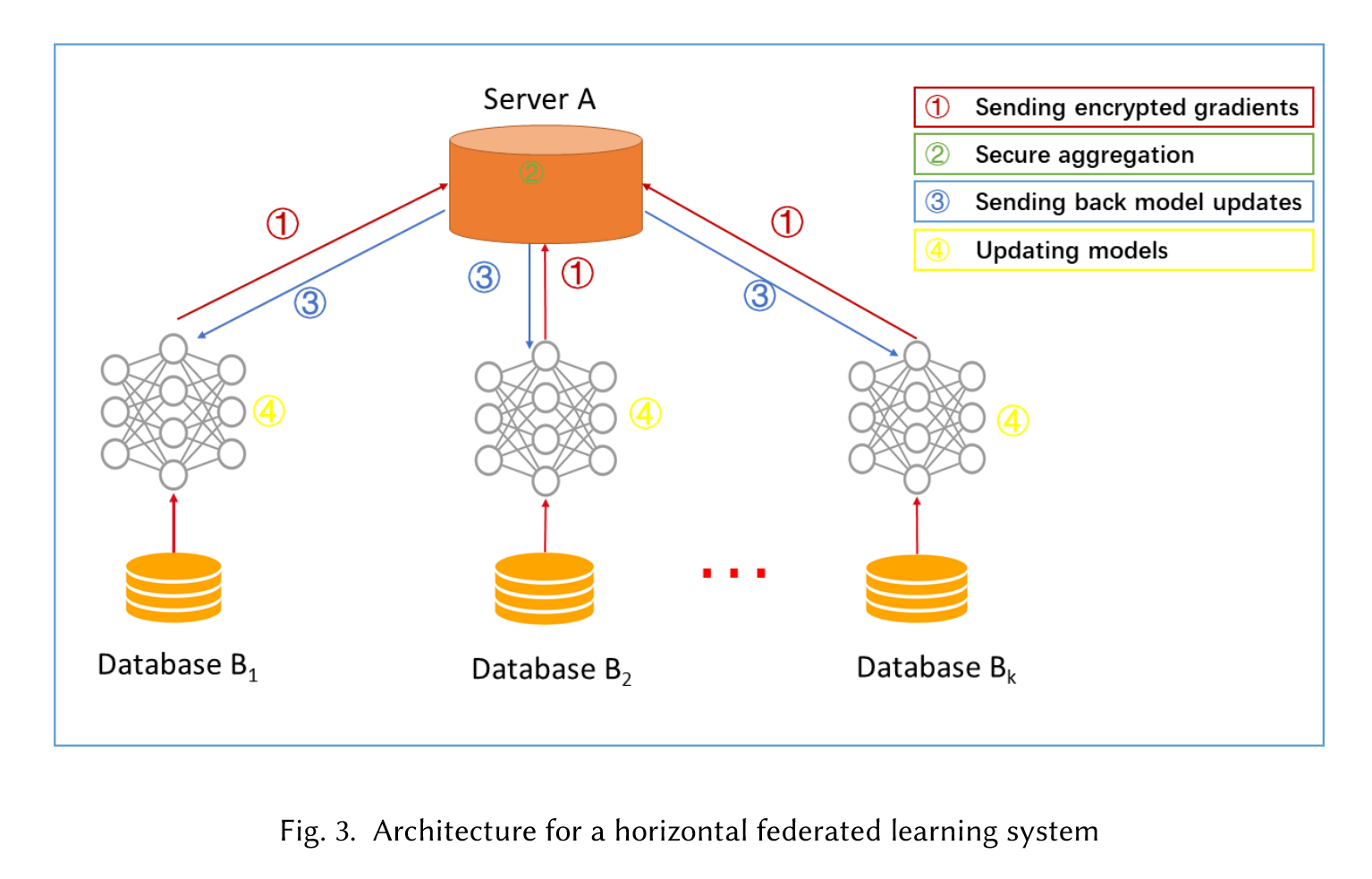
- 参与方各自从服务器A下载最新模型
- 每个参与方利用本地数据训练模型,加密梯度上传给服务器A,服务器A聚合各用户的梯度更新模型参数;
- 服务器A返回更新后的模型给各参与方;
- 各参与方更新各自模型。
纵向联邦学习
纵向联邦学习的本质是 特征的联合,适用于用户重叠多,特征重叠少的场景,比如同一地区的商超和银行,他们触达的用户都为该地区的居民(样本相同),但业务不同(特征不同)。
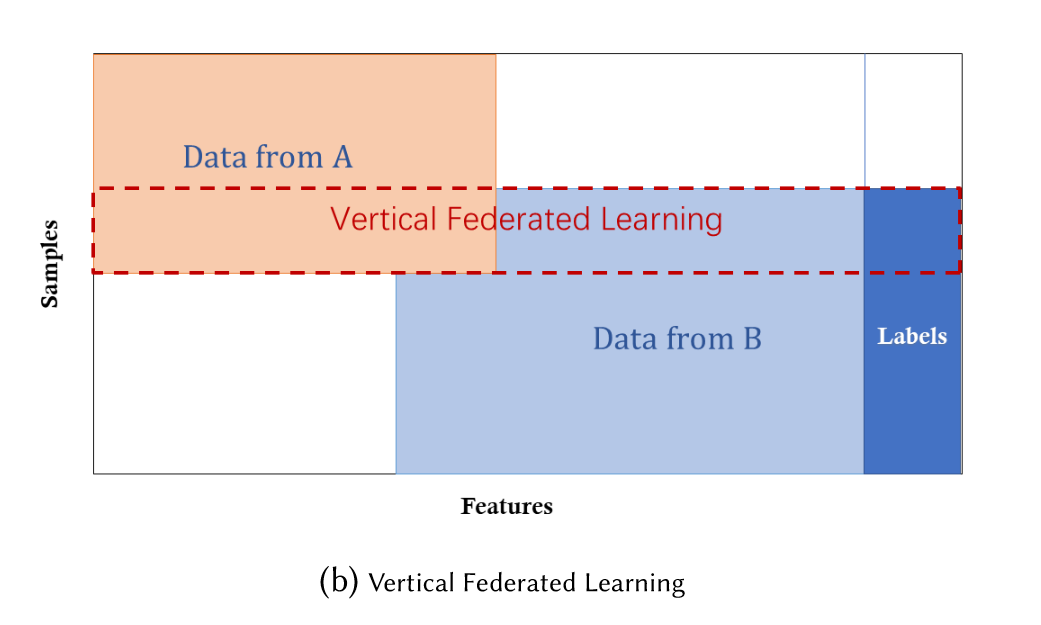
学习过程
纵向联邦学习的本质是交叉用户在不同业态下的特征联合,比如商超A和银行B,在传统的机器学习建模过程中,需要将两部分数据集中到一个数据中心,然后再将每个用户的特征join成一条数据用来训练模型,所以就需要双方有用户交集(基于join结果建模),并有一方存在label。其学习步骤如上图所示,分为两大步:
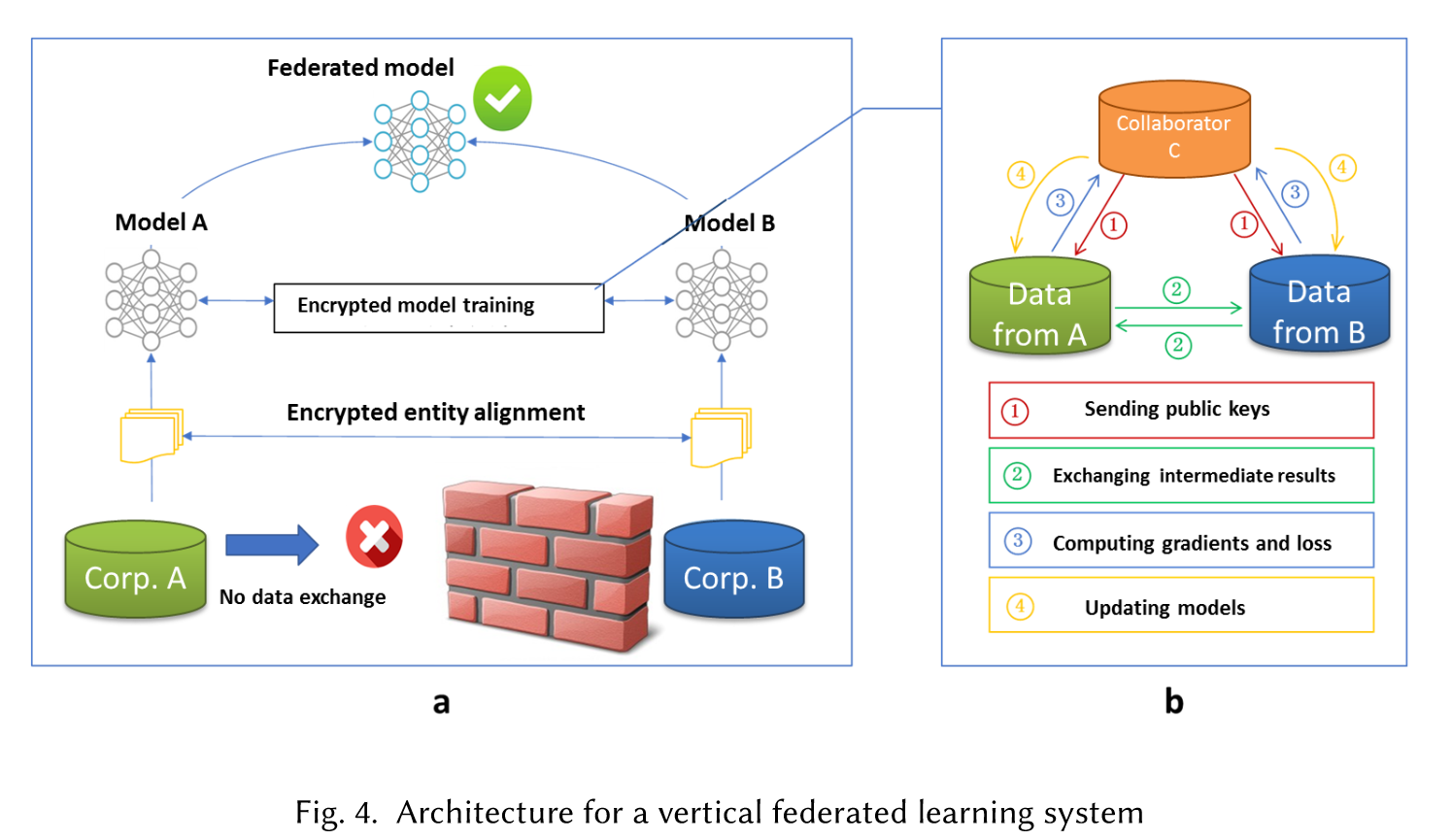
第一步:加密样本对齐。是在系统级做这件事,因此在企业感知层面不会暴露非交叉用户。
第二步:对齐样本进行模型加密训练:
- 由第三方C向A和B发送公钥,用来加密需要传输的数据;
- A和B分别计算和自己相关的特征中间结果,并加密交互,用来求得各自梯度和损失;
- A和B分别计算各自加密后的梯度并添加掩码发送给C,同时B计算加密后的损失发送给C;
- C解密梯度和损失后回传给A和B,A、B去除掩码并更新模型。
联邦迁移学习
当参与者间特征和样本重叠都很少时可以考虑使用联邦迁移学习,如不同地区的银行和商超间的联合。主要适用于以深度神经网络为基模型的场景。
迁移学习,是指利用数据、任务、或模型之间的相似性,将在源领域学习过的模型,应用于 目标领域的一种学习过程。