《Towards On-Device Federated Learning: A Direct Acyclic Graph-based Blockchain Approach》
目标
为了解决联邦学习中的设备异步和异常检测问题,同时避免由区块链导致的资源浪费
设备异步。传统的中心化和同步FL(Google FL),一个节点必须等待其他节点完成任务才能一起进入下一轮训练,一个崩溃的节点可能阻塞整个系统。
异常检测。一个节点的数据集和操作对其他节点是不可见的。一些恶意节点可能会破坏整个系统的准确度和降低效率。
主要贡献
提出了第一个基于DAG的FL异步框架来解决设备异步和异常节点检测问题。
DAG-FL 模型

“This feature promises that a node in DAG-FL can immediately participate in an iteration of FL whenever it is in idle state. When the node completes an iteration of FL and gets a new trained local model, the new local model can be published on its local DAG as a transaction immediately, and latter the new published transaction would be seen by all other nodes.” (Cao 等。, p. 4) (pdf) ”
还是用本地的数据来训练模型,并没有和其他节点做聚合?
“initial” (Cao 等。, p. 5) (pdf)
异步构架
FL Layer:
全局模型由存储在DAG中的本地模型使用FedAvg算法聚合产生,节点使用本地数据集进行训练。得到的新的模型被当作一个交易发布到DAG中。(每笔交易就是一个模型)
DAG Layer:
每个节点维护一个本地DAG,其中每个交易包含下相应的认证信息,本地模型参数,和许可链接。本地DAG通过广播和无线网络更新,最终一个新的交易可以得到传播。
Application Layer:
一个外部接口,通过智能合约发布任务。这个客户端可以观察整个FL过程的进展,从而控制整个FL的进行和停止。
异步性分析:
在整个DAG-FL中没有central server,每个节点是通过本地已有的模型来构建新的全局模型。节点可以在合适的时间来进行FL迭代,获取的新的模型发布在本地DAG,随后可以被其他节点所见。节点之间的行为互不影响可以异步进行。
共识算法
当一个节点完成一轮迭代,生成一个新的模型。他会从本地DAG选取几个tips(加入DAG但是没有被验证的block)来进行验证:
验证使用RSA等算法加密的身份证书。可以避免恶意节点的女巫攻击。
使用本地的测试集来计算模型的精确度。
然后选取模型精确度最高的几个模型来构成新的全局模型。
节点使用这个模型和本地数据集训练,得到的新模型通过一个新的交易发布到DAG中。
随着DAG的持续扩展,一个交易的每次认证都意味着这个交易代表的模型被选择去构建一个全局模型,进而影响最终模型的生成。得到的认证越多,它在FL中的影响越大。反之,节点就会被孤立,在FL中影响越小。
所以,最终DAG-FL训练的模型会向大多数节点期望的方向发展,少部分恶意节点会逐渐被孤立,影响降到最小化。
FL算法
符号定义:
D = {1,2,3,…,N $_D$ },代表整个设备集群。D $_i$是第i个节点。
S $_i$是D $_i$的训练集,|S $_i$| = N $_i$,这里N $_i$是S $_i$的samples数量。
D $_i$在本地创建一个仅自己可见的DAG为g $_i$,存储在其中的交易为w
时间t,在D $_i$训练得到的本地模型为w $_i$ $^t$
算法流程:
- D $_i$在t $_0$开始FL算法迭代,首先验证本地DAG的一些tips(验证他们的身份和用测试集验证准确度)
- 将准确度较高的的k个tips使用FedAvg算法聚合成一个全局模型: $$ \omega^{t_{0}}=\sum_{i=1}^{k} n_{i} \omega_{d_{i}}^{t_{i}} $$ 这里 n $_i$是表示模型重要性的权重因子,为了简化这里设置为1/k,表示同等重要。
- 节点从数据集S $_i$中提取m个samples作为一个最小batch z$_i$ 来对得到的全局模型训练 $\beta$个epochs.
- 得到一个新模型 $\omega {i}^{ t{0}}$,将它发布到$g_{i}$上。
DAG-FL 操作
这里介绍框架中的两个重要算法。
DAG-FL Controlling

在应用层的外接客户端可以认为是一个权威组织,负责任务发布任务。通过智能合约执行DAG-FL 控制算法。过程如上图。
DAG-FL Updating

节点在空闲时执行DAG-FL Updating 算法。
- 节点随机从本地DAG选取staleness范围在可以接收的tip。
- 节点先认证所选tips的身份,然后用自己的test数据集来计算所选tips的模型精确度。
- 选择精确度高的k个tips,使用FedAvging算法得到一个全局模型。节点用本地数据来训练这个全局模型。
- 一个新的交易被生成。包括身份信息,上一阶段训练得到的模型,和最k个tips的验证信息。
未来工作
- 在模型可用性上,使用一个小的test set可能对于一些特定场景不适合,考虑其他的异常检测方法。
- 信用评估
- 权重聚合。本文的模型使用的方法是同等权重系数的FedAvg,可以使用更好的方法来给高质量的模型更高的权重提高模型精度。
《Implicit Model Specialization through DAG-based Decentralized Federated Learning》
背景
由于联邦学习数据的非独立同分布特性,所有节点训练一个模型太过宽泛,提出一种基于DAG区块链的联邦学习框架,所有节点利用本地数据和其他节点相似的数据训练自己的特例化模型,和全局的泛化模型结合来提高系统的性能。
这篇论文是在联邦学习之前已经有的对本地数据特例化的研究基础上,引入DAG区块链。
模型
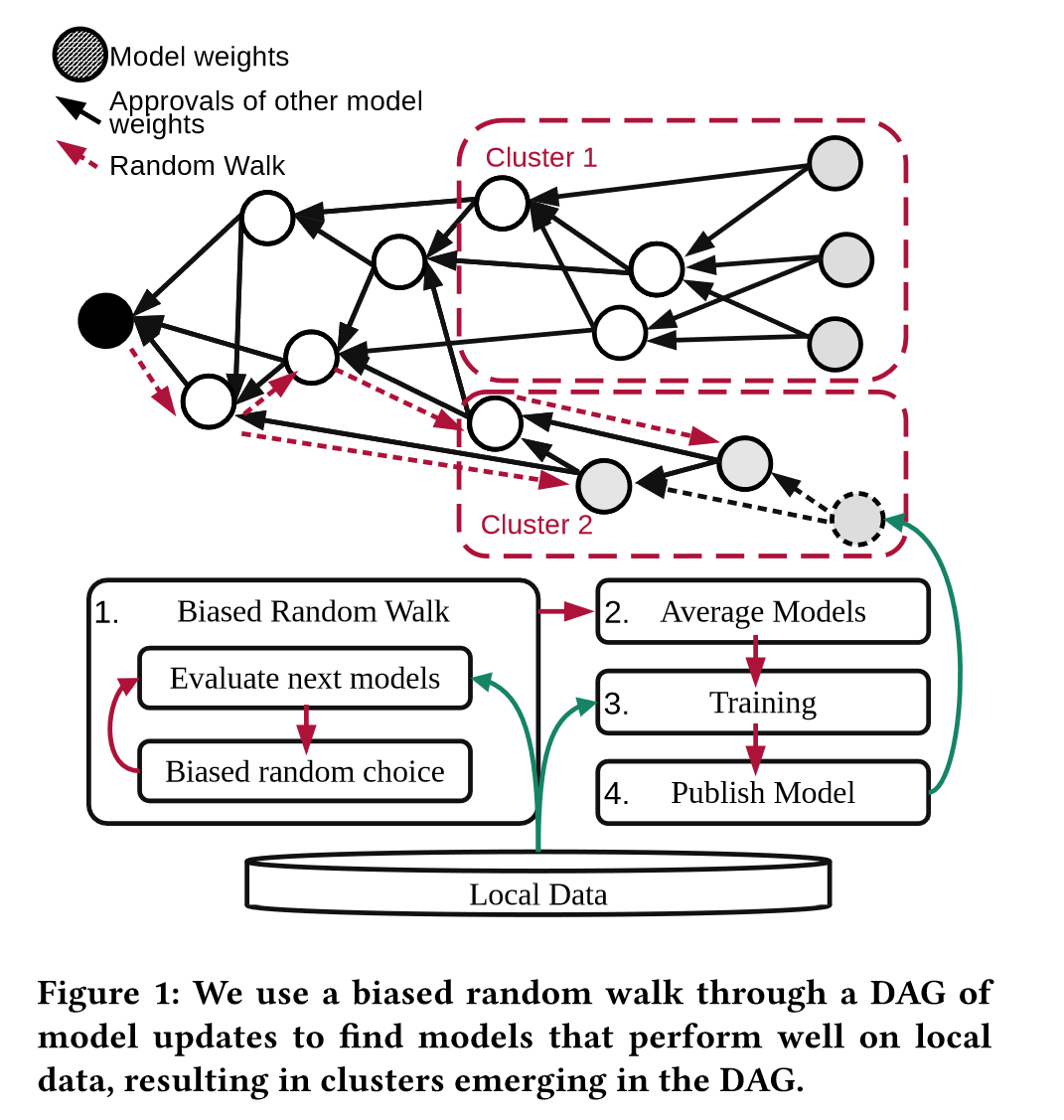
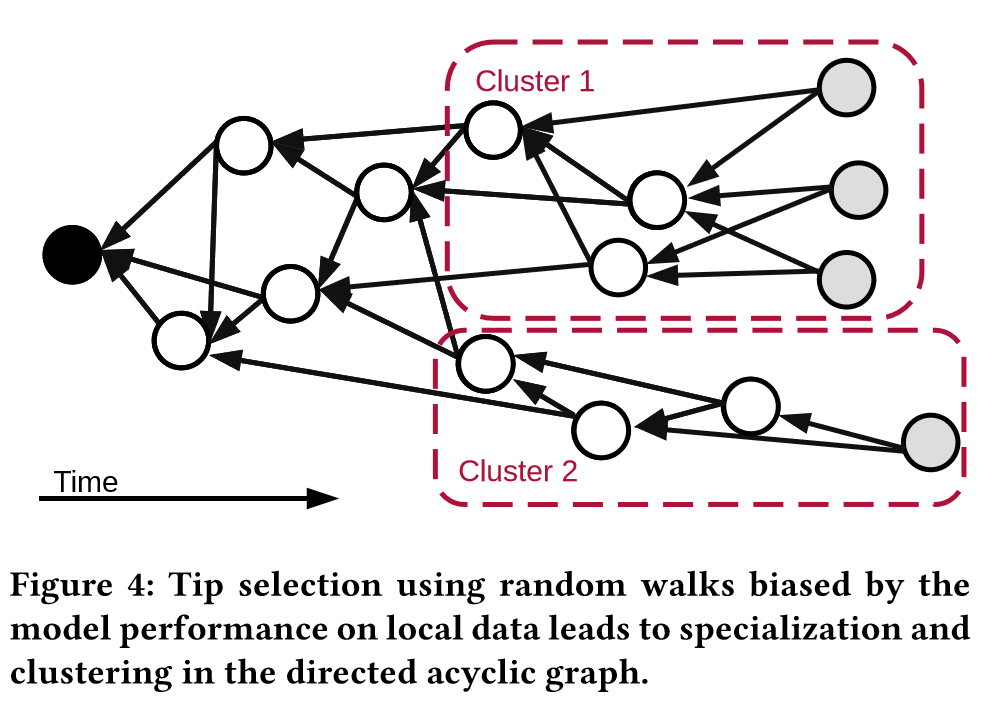
每个节点执行四个步骤,通过基础的随机移动算法选择DAG上的两个tips,将这个两个选择的模型参数平均,得到的模型在本地数据集上训练,如果最终得到的模型有提高就发布。
tips选择算法
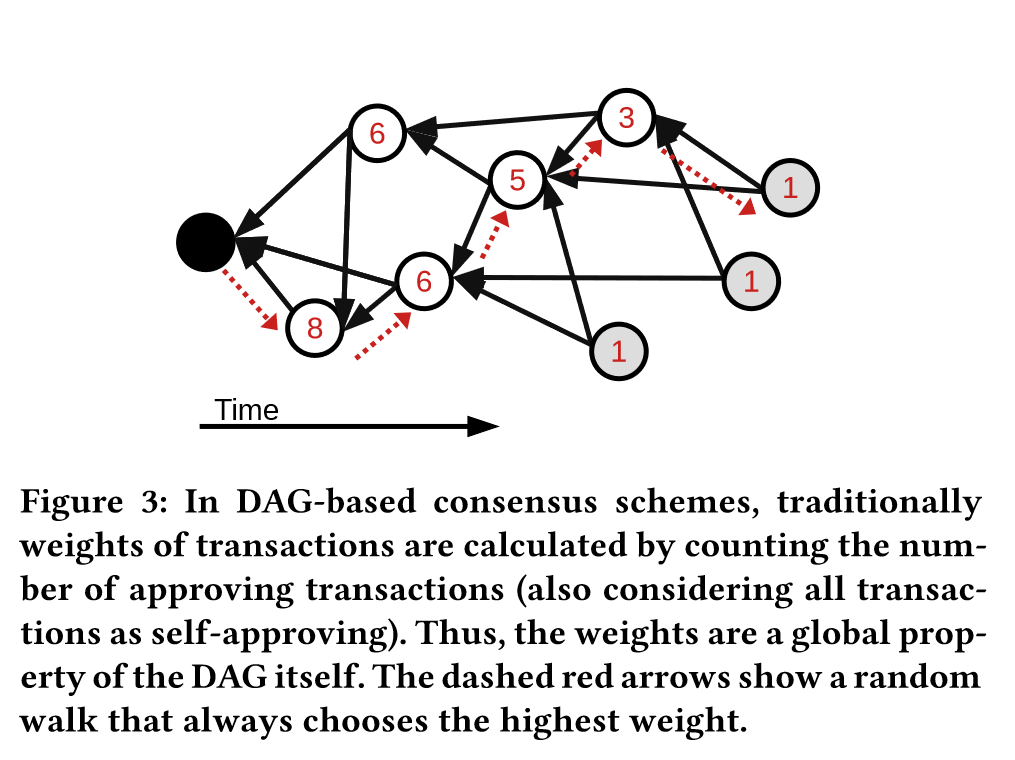 从区块链接的相反方向随机遍历。每个交易(区块)根据它的子图大小分配一个权重,通常会选择最高权重的区块,使得这个遍历方向收敛。
从区块链接的相反方向随机遍历。每个交易(区块)根据它的子图大小分配一个权重,通常会选择最高权重的区块,使得这个遍历方向收敛。

同时,对于每个节点有特定化的偏向处理,遍历的每一步,对于下一跳可以到达的潜在模型在本地数据集上进行评估。
WEIGHTEDCHOICE 函数从这些模型中随机选择,并根据子节点对本地数据的精确度进行加权。(到底是按照权重还是随机选择?)
这里的精确度计和权重计算:

遍历的随机性可以由 α 参数确定,其中值越大,权重之间的差异越大,因此随机性越小,确定性越高。另一方面,较小的 α 值会导致权重收敛,从而导致更多随机性。模型之间的预期精度差异取决于我们的方法所应用的机器学习问题,以及学习率、批量大小和局部时期等超参数。为了在模型之间的精度变化很小的情况下也能实现良好的特性化,即使在差异很大的情况下也能实现良好的泛化,将每个步骤中的精度分布 max(accuracies) - min(accuracies) 精度归一化 * 的一部分:

《SAFA: A Semi-Asynchronous Protocol for Fast Federated Learning With Low Overhead》
背景
原有的FedAvg算法存在一些问题:
- 同步开销大: 每轮迭代中央服务器需要传输全局模型给所有客户端,带宽达到一个峰值。
- 客户端利用不足:随机选择的客户端使得许多可以参加训练的客户端闲置。
这个论点不充分。FedAvg是在所有可用的客户端中随机选择一定比例,并不是完全随机的。
- 进度浪费: 被选中的设备如果在完成本地训练之前失败,则之前的工作都会作废。
- 每回合效率低: 在每轮结束进行聚合,FedAvg必须等待所有客户端完成。如果一些客户端故障,整个过程会等到超时结束。
模型
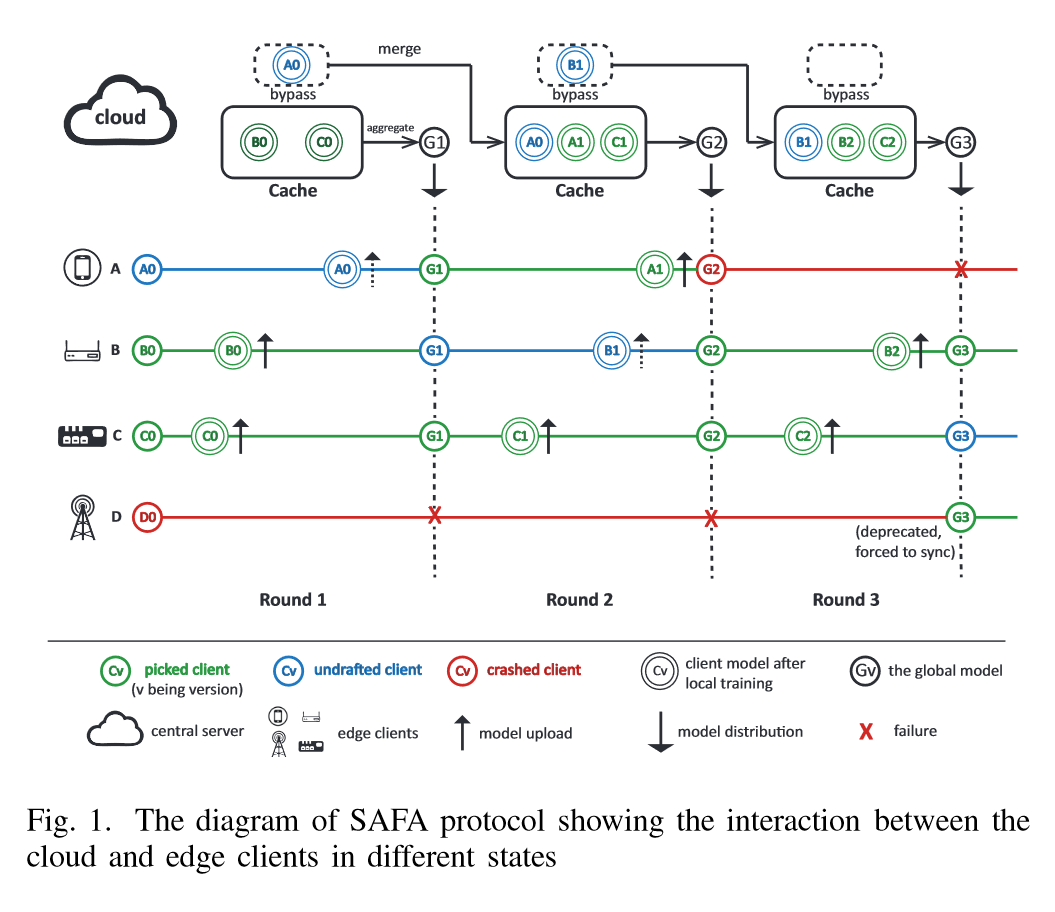
SAFA包括三部分: Lag-tolerant Model Distribution (滞后容忍模型分布),Compensatory First-Come-First-Merge (CFCFM) client selection [补偿性先到先合并 (CFCFM) 客户端选择], discriminative aggregation (判别聚合)
下面SAFA的一个系统图:
文中所用的参数表

Lag-tolerant Model Distribution
整个模块关键的有两点:
有选择的同步全局模型。
不像FedAvg算法一样每轮每个参与节点都要同步模型,这是一个交流密集的过程,开销很大。SAFA模型只要求两种类型必须同步。上一轮成功完成的节点(FedAvg中的正常节点)和被标记为过时的节点,这个过时节点是由于网络或者其他原因本地模型落后全局太多的客户端。这里有个滞后容忍参数 $\tau$,来调节这个滞后范围。
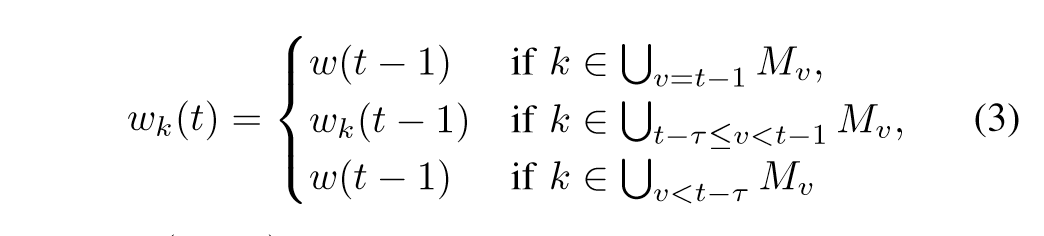
这里t-1表示上一轮的最新模型, $\omega _{k}$代表第k个节点的本地模型,$\omega$ 代表全局模型。可以看到,在 $t- \tau$ 范围内本地节点的滞后是可以容忍的。
没有被选中的节点也可以参与迭代。
没有被选中的节点也可以上传更新。这部分不会被直接合并,而是会通过一个bypass结构影响下一轮。 一个cache用来保存那些选中的节点上传的更新,没被选中的节点的更新保存在bypass中。bypass会在汇聚步骤完成后和cache合并,使得实际的有影响节点比率比参数C决定的更高。
Compensatory First-Come-First-Merge (CFCFM) client selection
代替必须等待所有选中节点上传更新,SAFA采用先来先合并方法,只要上传的更新达到所需要的比率(是不是意味着可以上传的节点大于实际所需要的节点)就可以执行合并操作。
给予那些参与较少的客户更高的优先级。在每一轮中,服务器都会维护一个错过上一轮训练的客户端的 id 列表,它们上传的更新会优先选择。

Discriminative Aggregation
聚合算法如下:

对于选择的客户端,它们的更新将在合并到全局模型后保留在缓存中。对于未选择的客户端,更新不会在本轮生效,但会被缓存带入下一轮。对于崩溃的客户端,只有在它们没有被弃用的情况下,它们的模型才会保持不变。
算法流程

每轮开始时,服务器先检查客户端的模型,根据给定的超参数$\tau$和滞后容忍算法来分配模型。服务器收集上传的更新,错过上次更新的节点会被优先采集。等采集到的更新满足预先设置的标准后,执行三步合并,然后更新缓存状态。